k-NN algorithm is trained on labelled categorical data and it is used to classify unlabelled categorical data. The k-NN algorithm is a supervised and a nonparametric approach. The intution behind k-NN is to consider the most similar other items defined in terms of their attributes, look at their labels, and give the unassigned item the majority vote.
For example, if you had a bunch of movies that were labelled“thumbs up” or “thumbs down,”and you are looking to rate a new movie that hasn’t been rated. First you could look at its attributes such as movie length, genre, number of sex scenes, number of Oscar winning actors, then you could find other movies with similar attributes, and then give the rate to new movie.
Two things need to be considered for k-NN algorithm: (a) how you define similarity or closeness, (b) how many neighbors you should look at which is value of k.
✓ Overview of the kNN process,
✶Decide on your similarity or distance metric.
✶Split the original labeled dataset into training and test data.
✶Pick an evaluation metric (Misclassification rate).
✶Run k-NN a few times, changing k and checking the evaluation measure.
✶Optimize k by picking the one with the best evaluation measure.
✶Once you have chosen k, use the same training set and now create a new test set that you have no labels for, and want to predict.
✓ Similarity distances:
✶Euclidean distance – Euclidean distance belongs to a family of the Lr-Norm distance. A space is defined as a Euclidean space if the points in this space are vectors composed of real numbers. It’s also called the L2-norm distance. It can be plotted on a plane or in multidimensional space.
✶Cosine distance – In the spaces where the points are considered as directions, the cosine distance yields a cosine of the angle between the given input vectors as a distance value. It will yield a value between –1 (exact opposite) and 1 (exactly the same) with 0 in between meaning independent.
While using the cosine distance, we need to check whether the underlying space is Euclidean or not. If the elements of the vectors are real numbers, then the space is Euclidean, if they are integers, then the space is non-Euclidean. The cosine distance is most commonly used in text mining. In text mining, the words are considered as the axes, and a document is a vector in this space. The cosine of the angle between two document vectors denotes how similar the two documents are.
✶Jaccard’s distance – This gives the distance between a set of objects. It is the ratio of the sizes of the intersection and the union of the given input vectors.
✶Hamming distance – It can be used to find the distance between two strings or pairs of words or DNA sequences of the same length. With two bit vectors, the Hamming distance calculates how many bits have differed in these two vectors.
✶Manhattan or city block distance – This is also a distance between two real-valued k dimensional vectors. It’s an L1-norm distance. By passing an r value as 1 to the Lr-norm distance function, we will get the Manhattan distance.
When using these distances in algorithms, we need to be mindful about the underlying space.
✓ Training and test sets
For any machine learning algorithm, the general approach is to have a training phase, during which you create a model; and then you have a testing phase, where you use new data to test how good the model is.
In our case, kNN is trained on labelled data in the training phase. In testing, you pretend you don’t know the true label and see how good you are at guessing using the k-NN algorithm.
To do this, you will need to save some clean data from the overall data for the testing phase. Usually you want to save randomly selected data (80/20 rule).
✓ Evaluation metric
Evaluation metric is used find whether model is doing good job. The accuracy, which is the ratio of the number of correct labels to the total number of labels, and the misclassification rate, which is just 1–accuracy. Minimizing the misclassification rate then just amounts to maximizing accuracy.
✓ Selecting the value of K
You just need to try a few different k’s and see how your evaluation changes. So you will run kNN a few times, changing k, and checking the evaluation metric each time.
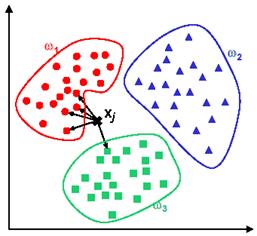
In the above example in Figure, we have three classes and the goal is to find a class label for the unknown example xj . In this case we use the Euclidean distance and a value of k=5 neighbours. Of the 5 closest neighbours, 4 belong to w1 and 1 belongs to w3, so xj is assigned to w1, the predominant class.
✓ Following things are considered when applying kNN algorithm,
✶Data is in some feature space where a notion of distance makes sense.
✶Training data has been labelled or classified into two or more classes.
✶You pick the number of neighbours to use, k.
✶You are assuming that the observed features and the labels are somehow associated.
✶They may not be, but ultimately your evaluation metric will help you determine how good the algorithm is at labelling. You might want to add more features and check how that alters the evaluation metric. You would then be tuning both which features you were using and k. But as always, you are in danger here of over fitting.

[…] [5] k-Nearest Neighbors (k-NN) […]